NVIDIA DGX POD racing: Qualifying laps


Joey Parnell
NVIDIA GTC 2021 has just wrapped up with several joint announcements from NVIDIA and NetApp. NetApp shares with NVIDIA a vision and history of optimizing the full capabilities and business benefits of artificial intelligence for organizations of all sizes. The NVIDIA DGX A100 system is a next-generation universal platform for AI that deserves equally advanced storage and data management capabilities from NetApp.
At the heart of NVIDIA DGX A100 systems are 8 NVIDIA A100 Tensor Core GPUs; 6 NVSwitches built on third-generation NVLink technology for high-speed GPU-to-GPU communications; 8 Single-Port Mellanox ConnectX-6 HDR (high data rate) 200Gb/s InfiniBand host channel adapters (HCAs) for compute traffic; and 1 or 2 Dual-Port Mellanox ConnectX-6 HDR HCAs for external storage traffic that can run HDR speeds up to 200Gb/s InfiniBand or Ethernet.
 Source: NVIDIA DGX A100 System Architecture
Source: NVIDIA DGX A100 System Architecture
The NVIDIA DGX POD reference architecture combines DGX A100 systems, networking, and storage solutions into fully integrated offerings that are verified and ready to deploy. NetApp and NVIDIA are partnered to deliver industry-leading AI solutions. As an NVIDIA partner, NetApp offers two solutions for DGX A100 systems, one based on NetApp® ONTAP® AFF and the other based on NetApp EF-Series EF600 with BeeGFS. If your enterprise plans to run many distributed jobs using GPUs or partial vGPUs on an as-needed basis, and if you plan to use NFS and the rich data management functionality available in ONTAP, AFF solutions are a great fit. If you have fewer jobs using GPUs for long-running training operations and require the extreme performance of a parallel file system, consider E-Series solutions. Both solutions are accompanied by a reference architecture that includes observed bandwidth, IOPS, and training performance results under certain testing conditions.
Other storage solution vendors have published reference architectures as well, but they offer a motley set of results that superficially appear to paint some solutions as significantly superior to others. Readers are left to wonder: What do these results mean and how are we to interpret them? Are we POD racing on the same course?
First, a bit of a deeper dive into the DGX A100 system architecture. Recall that there are 8 ConnectX-6 HCAs intended for intra-DGX A100 compute traffic, and there are 1 or 2 dual-ported ConnectX-6 HCAs intended for external storage traffic. This means that for a real-world use case, the upper limit of single DGX A100 system storage throughput is the storage throughput of 1 or 2 dual-ported ConnectX-6 HCAs. NetApp’s approach to validation in the lab is based on real-world use cases. In this process, an external storage system serves data to multiple DGX A100 systems that work in concert, keeping NVLinks (and ultimately GPUs) busy using NVIDIA Collective Communications Library (NCCL) for distributed deep learning (DL) training and high-performance computing.
Let’s dive into our impressive qualifying laps.
Hardware requirements (EF-Series EF600 validation)
| Hardware | Quantity | Rack Units |
| NVIDIA DGX A100 systems | 8 | 48 |
| NetApp EF600 storage system | 2 high-availability (HA) pair, includes 24x 1.92TB NVMe SSDs on each | 4 |
| NVIDIA QM8700 HDR IB switches | 2 for compute cluster interconnect | 2 |
| 2 for DGX access to BeeGFS servers | 2 | |
| Lenovo SR655 servers | 4 running BeeGFS server services | 8 |
FIO benchmark parameters
| Solution | NetApp EF600 + BeeGFS |
| I/O type | Direct |
| Block size (BW/IOPS) | 1MB / 4KB |
| I/O (file) size | 4GB |
| I/O engine | posixaio |
| I/O depth | 64 |
| Jobs (BW/IOPS) | 64 / 64 |
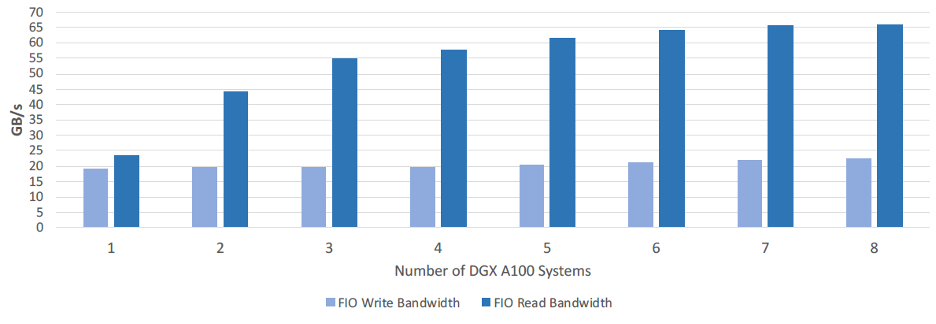 Source: NetApp Verified Architecture: NetApp EF Series AI with NVIDA EGX A100 Systems and BeeGFS
Source: NetApp Verified Architecture: NetApp EF Series AI with NVIDA EGX A100 Systems and BeeGFS
Synthetic benchmarks are useful for understanding theoretical limits, but let’s see what a real-world application looks like with an MLPerf Training v0.7 ResNet-50 benchmark test. This is an industry-standard benchmark to validate DL infrastructure performance. The highlight of the MLPerf results is seeing near linear scaling in training throughput.
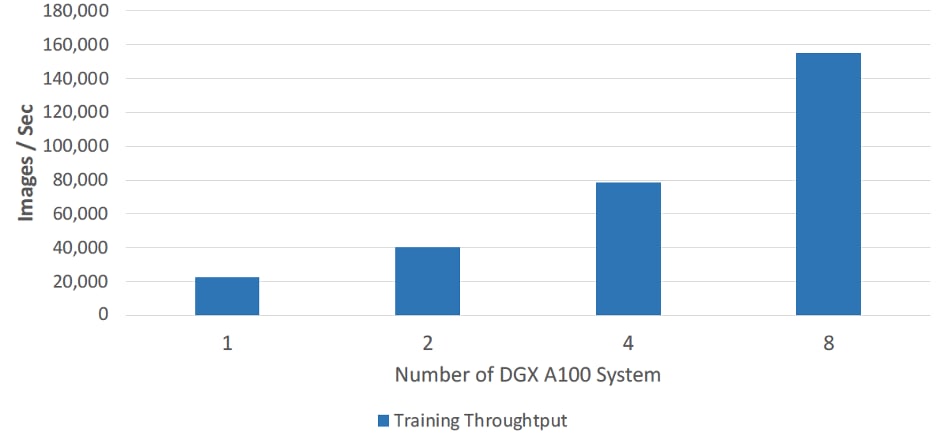 Source: NetApp Verified Architecture: NetApp EF Series AI with NVIDA EGX A100 Systems and BeeGFS
Source: NetApp Verified Architecture: NetApp EF Series AI with NVIDA EGX A100 Systems and BeeGFS
Looks like you need a pit stop, buddy.
Our experience running these MLPerf benchmarks on DGX A100s shows us that in practice the test generates between 2 and 3GB/s of storage traffic per DGX A100, and that during these runs the storage systems have significant headroom. Based on those observations, we can see that our storage solutions are typically not the bottleneck until a significant number of DGX A100s is reached. We can extrapolate that with synthetic benchmark results to guide solution sizing. The goal of POD racing is to keep several DGX A100 systems consistently and efficiently fed with data.At the end of the day, MLPerf is a specific benchmark for DL infrastructure training and performance. Storage workloads come in all shapes and sizes, depending on the use case and the nature of the analytics or AI employed. NetApp solutions can accommodate a wide range of workloads for AI and analytics.
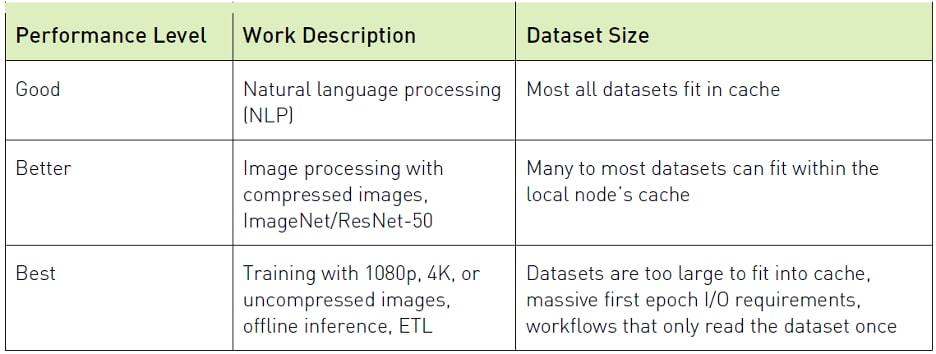 Source: NVIDIA DGX SuperPOD: Scalable Infrastructure for AI Leadership (RA-09950-001)
Source: NVIDIA DGX SuperPOD: Scalable Infrastructure for AI Leadership (RA-09950-001)
Fast isn’t enough for AI: Now this is pod racing.
We’ve shown that NetApp EF-Series EF600 systems with BeeGFS easily support the DL training workload generated by 8 DGX A100 systems. For larger deployments with higher storage performance requirements, additional building block systems can be seamlessly added to the BeeGFS namespace to achieve massive multi-PB scale with linear performance scalability.We hit these numbers with a real-world setup. If you look closely at some competing solutions, you may notice impractical architectures designed to put up a flashy number to a small number of DGX A100 systems. But as we’ve demonstrated, the DL training generated by this benchmark shows that storage performance isn’t the significant bottleneck. The proven real-world architecture we’ve demonstrated scales far beyond 8 DGX A100 systems. The race is to keep GPUs fed at scale for AI and HPC workloads solving real problems and delivering desired customer outcomes.
NetApp’s leadership in data management brings a comprehensive data fabric and portfolio of solutions to AI workloads. We deliver container-native and cloud-native data management capabilities with Container Storage Interface (CSI) drivers. We make storage easy to use for data scientists with the NetApp Data Science Toolkit. That is the data challenge around AI. Performance gets you in the race, but data management is the turbo booster.
Pardon our exhaust.
Visit us at the NetApp GTC21 landing page to learn more about how NVIDIA and NetApp work together to drive value from AI.
Joey Parnell
Joey Parnell is a software architect and development lead at NetApp in the E-Series product group, responsible for reliability, availability, and data security features. Recently his focus has been technical leadership on durable, performant, reliable storage for video surveillance and AI solutions.