Speed up your data science initiatives


Mike McNamara
 Fast experimentation and successful business outcomes of AI are directly correlated, but many AI projects are rife with inefficient processes. The combination of data processing time and outdated storage solutions creates bottlenecks and workload orchestration issues, and static allocation of GPU compute resources limits the number of experiments that researchers can run.
Fast experimentation and successful business outcomes of AI are directly correlated, but many AI projects are rife with inefficient processes. The combination of data processing time and outdated storage solutions creates bottlenecks and workload orchestration issues, and static allocation of GPU compute resources limits the number of experiments that researchers can run.
NetApp and Run:AI have partnered to simplify the orchestration of AI workloads, streamlining the process of both data pipelines and machine scheduling for deep learning (DL). With the NetApp® ONTAP® AI proven architecture, you can fully realize the promise of AI and DL by simplifying, accelerating, and integrating your data pipeline. And to help your researchers manage and optimize GPU utilization, Run:AI’s orchestration of AI workloads adds a Kubernetes-based scheduling and resource utilization platform.
Together, NetApp and Run:AI products enable numerous experiments to run in parallel on different compute nodes, with fast access to many datasets on centralized storage. With the combined solution from NetApp, NVIDIA, and Run:AI, you get an infrastructure stack that is purpose-built for enterprise AI workloads.
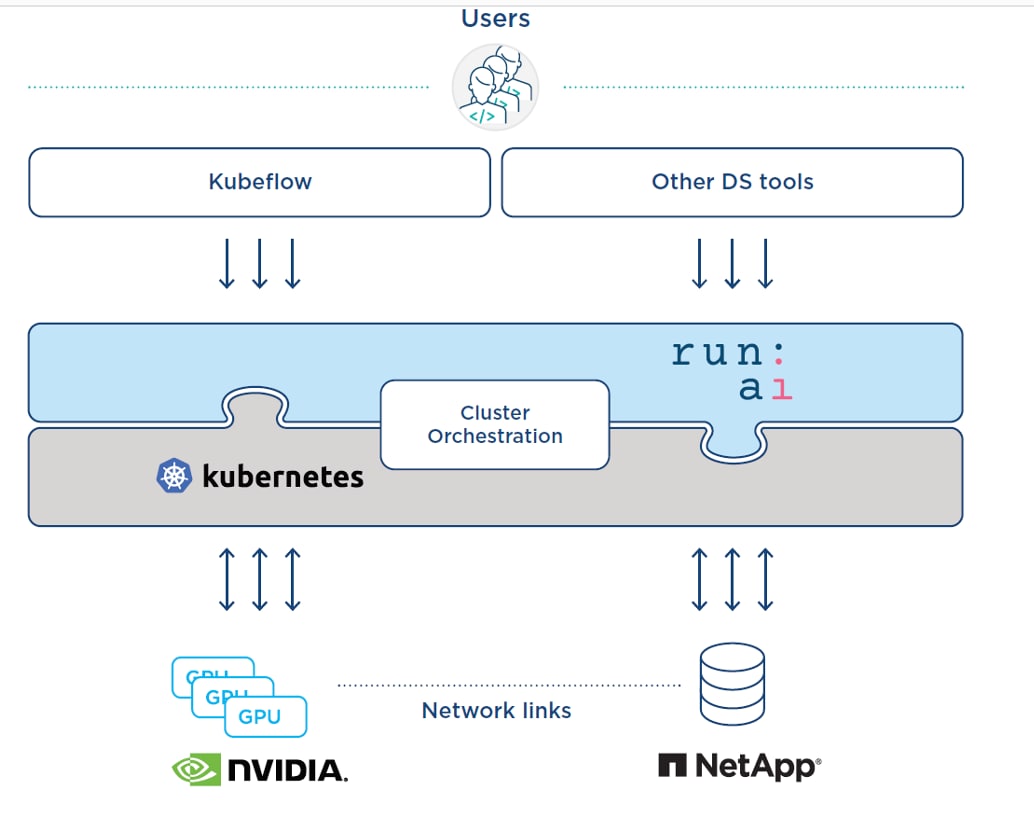 By using Run:AI’s centralized resource pooling, queueing, and prioritization mechanisms together with NetApp ONTAP AI, your researchers are removed from infrastructure management hassles and can focus exclusively on data science. You can increase productivity by running as many workloads as you need without bottlenecks in your compute or data pipeline. And with the Run:AI scheduler and virtualization technology, you can easily use fractional GPUs, integer GPUs, and multiple nodes of GPUs for distributed training on Kubernetes. In that way, AI workloads run based on need, not on capacity. Your data science teams can run more AI experiments on the same infrastructure.
By using Run:AI’s centralized resource pooling, queueing, and prioritization mechanisms together with NetApp ONTAP AI, your researchers are removed from infrastructure management hassles and can focus exclusively on data science. You can increase productivity by running as many workloads as you need without bottlenecks in your compute or data pipeline. And with the Run:AI scheduler and virtualization technology, you can easily use fractional GPUs, integer GPUs, and multiple nodes of GPUs for distributed training on Kubernetes. In that way, AI workloads run based on need, not on capacity. Your data science teams can run more AI experiments on the same infrastructure.
 With NetApp and Run:AI technology, if your company scales AI, you get a double benefit: faster experiments and full resource utilization. To learn how to streamline and accelerate your data science initiative, read the technical report.
With NetApp and Run:AI technology, if your company scales AI, you get a double benefit: faster experiments and full resource utilization. To learn how to streamline and accelerate your data science initiative, read the technical report.
Mike McNamara
Mike McNamara is a senior leader of product and solution marketing at NetApp with 25 years of data management and data storage marketing experience. Before joining NetApp over 10 years ago, Mike worked at Adaptec, EMC and HP. Mike was a key team leader driving the launch of the industry’s first cloud-connected AI/ML solution (NetApp), unified scale-out and hybrid cloud storage system and software (NetApp), iSCSI and SAS storage system and software (Adaptec), and Fibre Channel storage system (EMC CLARiiON). In addition to his past role as marketing chairperson for the Fibre Channel Industry Association, he is a member of the Ethernet Technology Summit Conference Advisory Board, a member of the Ethernet Alliance, a regular contributor to industry journals, and a frequent speaker at events. Mike also published a book through FriesenPress titled "Scale-Out Storage - The Next Frontier in Enterprise Data Management", and was listed as a top 50 B2B product marketer to watch by Kapos.