Real-World Experiences with NetApp Cloud Data Services – Part 1: Cloud Volumes ONTAP


Ryan Beaty
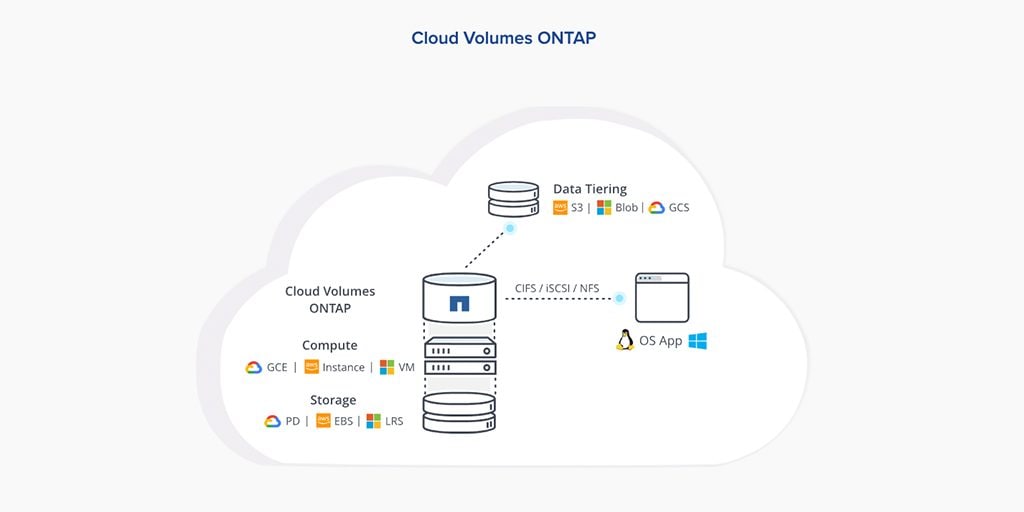 I recently had a lot of time to play with NetApp’s new cloud services including Cloud Volumes ONTAP (CVO) and Azure NetApp Files (ANF). In these 2 blog posts, I’ll describe my experiences with both CVO and ANF. I think these are great products that you can't get inside of Azure or AWS by themselves. They fill a lot of gaps that are in a lot of people’s cloud environments today, you just need to be smart in how you're deploying and using them. Hopefully my insights will be useful to you in your own implementations.
I recently had a lot of time to play with NetApp’s new cloud services including Cloud Volumes ONTAP (CVO) and Azure NetApp Files (ANF). In these 2 blog posts, I’ll describe my experiences with both CVO and ANF. I think these are great products that you can't get inside of Azure or AWS by themselves. They fill a lot of gaps that are in a lot of people’s cloud environments today, you just need to be smart in how you're deploying and using them. Hopefully my insights will be useful to you in your own implementations.
In this first blog, I’ll start with CVO.
I think a lot of people have a misconception about CVO. They think. "Hey, I have NetApp now and I have a DR location. Let me just spin up CVO inside of Azure or AWS and then I'll have a DR play there and I won't have to do my colo facility anymore." This might work for some cases but at the end of the day, it really comes down to how your environment is set up.
Most people forget that even if they just SnapMirror their data to CVO, the majority of implementations are running VMware. Now that you're running VMware and you SnapMirror your data store into Azure, how are you going to turn it on?
Back when VMware came out, everyone wanted to know, "How do I get my physical server onto the virtual platform?" VMware offered a P2V tool where you would P2V that into the virtual environment. Now you throw away your physical server and you're good to go. That's kind of what CVO is, if you want to think of it that way. It basically takes your NetApp system and virtualizes it, then throws it into Azure. For people using VMware, I say, "I just P2V'ed your NetApp."
You also have to think about migrating the data in your VMs into locally attached LUNs so all your data can reside in LUNs on the NetApp system instead of, say, a local drive in a VMDK. That way when you do stand up a virtual machine instance on Azure, it can then attach down to those LUNs so you can stand up your server. That's really going to be the only way CVO and SnapMirror are going to facilitate that DR location. That being said, it's possibly going to require a re-architecture in some environments just to be able to utilize CVO correctly.
Extending CVO past disaster recovery
In addition to DR, CVO is also makes the following much easier:- DevOps. You can put the data up there, clone it with FlexClone, and not get charged for multiple copies of the data.
- Data security. A lot of organizations have audits and have to identify who has access to the data. Encryption is a big key to that. Azure and AWS can encrypt your data, but who has access to the encryption keys and who can decrypt it? In Azure and AWS, you have no idea who actually has access to this stuff. With CVO, I can stand up a CVO instance and do NetApp Volume Encryption (NVE), then when I do my audit, the only people who have access to that controller are going to be internal employees. I can easily specify who has access to that data. It's very good for people who are security-conscious to know what data is going to be in the cloud and who has access to it.
- Data mobility. If you're currently running NetApp, CVO can help you seamlessly move data from your on-premises infrastructure to the cloud, and back and forth from cloud to cloud, such as AWS to Azure. If you want a multi-cloud environment, it's a lot easier to do with CVO because you can stand up two CVO instances.
- Cost savings. Because CVO allows for fabric pooling, you can simply peel off storage to a cheaper tier that's not being accessed all the time, helping you save money.
Setting up and running CVO
Installing and licensing CVO is very straightforward and easy. NetApp changed their install wizard a couple of times and it's a lot better now. You just bring your own license (BYOL), meaning that you purchase the license from NetApp. You will then get serial numbers. You're going to pay for the compute and storage separately from NetApp. Then when a license comes in, you can utilize it when you setup the CVO instance. You can also do a Pay-As-You-Go (PAYGO) license model, which you will get billed monthly for.To run my performance test, I created a virtual machine inside of my Azure environment and then set up different drives with Azure managing disks. I tried to mimic as close to a SQL workload as I could using I/O meter and stacked up the queue links so that we were not waiting on each queue to be processed. What I found was that the speeds were just out of the ballpark. It was a completely different league than Azure managed disks.
I started wondering why CVO HA is so much faster since it still uses the same types of drives in the background. CVO uses disk stage blocks, but they’re still performance drives.
Azure is going to deliver different throughput and I/O maximum depending on the size of your drive. Because of this, we’re going to have to start thinking about how we're going to size CVO in these environments. This is similar to how we thought about sizing NetApp controllers or even just a regular storage array 10 years ago. Back in the day when someone said, "Hey, I need 10,000 IOPS, what do we do?", we would always say, "Okay, what kind of drives are you running? Oh, 10K drives? Okay, that's about 125 IOPS per drive. So I need 10,000 divided by 125." That’s the way I figured out how many spindles I needed to be able to push 10K IOPS workloads.
Today we're starting to go back to that sizing methodology. Every time you size CVO, when you first stand up the CVO instance, you're going to pick your drive size. That drive size is essentially the same as the physical hardware size. You've got 500GB, 1TB, 2TB, 4, 8, etc., then it goes up depending on your VM.
Let's just take the standard one, two, four, and eight terabyte drives as an example. If you stand up the CVO instance for the first time with 600GB of user data, you can use two 500GB drives or one 1TB drive. If you decide on one 1TB drive CVO instance you’ll be able to fit the 600GB, but the throughput and IOPS limit is going to be different than if you use two 500TB drives.
The space is the same, but with two 500GB drives, you get more throughput and more I/O. It could come down to, "Well I've got so much space that if I needed 10TB, I would rather have multiple 500GB drives because I'm going to get more throughput and lower latency than if I just did a one 10TB drive or two 8TB drives." Now we're back to old-school sizing on CVO and ensuring that whatever we're creating fits within the profile that the customer needs.
As I pondered why CVO is so much faster, even though it uses the same underlying disks as Azure, I remembered WAFL always acknowledges the writes even though they're not written down yet to disk. It acknowledges it, sends back the acknowledgement, and then it's written during a CP flush. If we're in a situation in Azure or AWS where a virtual machine is not performing well and we're on premium SSDs, we've done what we can do. CVO would be a huge benefit in that instance because we can put as many disks behind it to get the throughput that we need. Then we can create a LUN or NFS share and hopefully eliminate our performance issues.
CVO eliminates the boundary that we get with cloud storage performance. I think that's fantastic because now there's no excuse to not go into cloud because of performance problems.
I hope these insights are helpful to you in your decision to purchase a cloud data service. Stay tuned for my next blog about Azure NetApp Files.
Ryan Beaty
Ryan is a leading IT expert and NCIE-certified NetApp Systems Engineer, with extensive knowledge in NetApp, Azure, VMware, Cisco, and enterprise technologies. He has even earned a coveted spot on the NetApp A-Team as a NetApp Advocate. Ryan has engineered and administered systems and cloud networks since 2005 and currently holds certificates in many relevant technologies. Ryan’s primary role at Red8 as a Sr. Systems Engineer is to architect and implement sophisticated technology solutions for customers, including cloud. Along with understanding how the technology works, and what the limitations are, his personal goal is to provide the highest quality available, and to paint a clear picture of exactly what the end goal will look like before the implementation begins.