Microsoft SQL Server Big Data Clusters with NetApp StorageGRID


Joseph Kandatilparambil
The rapid adoption of object storage has transformed how customers manage data at scale. Traditional storage and the resources required to manage it become unworkable as datasets of hundreds of petabytes become the norm. Object storage leveraging the S3 API is now the de facto standard for both public and private cloud. Customers seek to turn these massive datasets from a burden into a competitive advantage by leveraging analytics. In doing so, they need tools that can span public and private cloud, extending their data lake to get a total view of their data.
Starting with Microsoft SQL Server 2019, SQL Server Big Data Clusters allow you to deploy clusters of SQL Server, Spark, and HDFS containers on Kubernetes. With these components, you can combine and analyze high-value relational data with high-volume unstructured data. This means that customers who have data on their S3 object store can now make their S3 data available to their SQL Server Big Data Clusters for analytics.
Over the past month, teams at NetApp and Microsoft have been working together to provide customers with the ability to use NetApp® StorageGRID® S3 object storage as part of big data analytics on Microsoft SQL Server Big Data Clusters by leveraging SQL Server PolyBase. This enables customers to run big data analytics with objects available on their StorageGRID by simply mounting StorageGRID buckets to their SQL Big Data Cluster.
Note: See below for the steps to use NetApp StorageGRID as an S3 end point for your big data cluster.
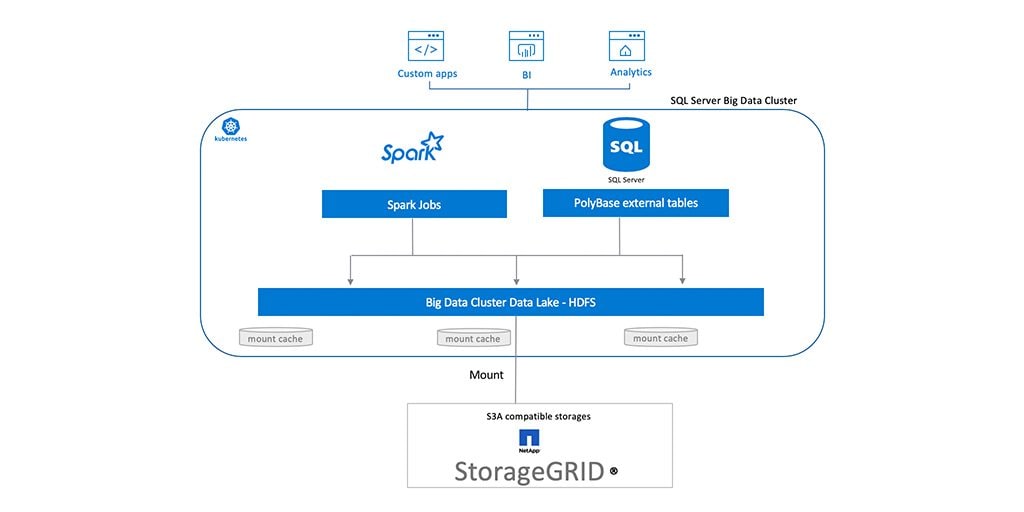 Figure 1) HDFS tiering using StorageGRID on Microsoft’s SQL Server Big Data Cluster.
Figure 1) HDFS tiering using StorageGRID on Microsoft’s SQL Server Big Data Cluster.
The StorageGRID industry-leading S3 object store offering enables you to have an S3 object store on the premises. StorageGRID software-defined object storage can be deployed in any combination of software-defined or purpose-built appliances and in virtualized environments. In a single namespace, StorageGRID can scale up to 16 data centers located around the world. StorageGRID offers massive S3 object storage and dynamic data management, enabling customers to run next-generation workflows on the premises, alongside their public cloud. The StorageGRID unique data management policy engine ensures optimized levels of performance and durability, as well as adherence to data locality requirements.
To Mount StorageGRID on SQL Big Data Cluster for HDFS Tiering
1) With a SQL Server Big Data Cluster running, open a terminal session to connect to your big data cluster. Find the IP address of the end point controller-svc-external service in your cluster.kubectl get svc controller-svc-external -n <your big data cluster name>2) Using the IP of the controller end point, log in to your big data cluster.
azdata login -e https://<IP of controller-svc-external>:30080/
3. Set the environmental variables of the S3 bucket on StorageGRID that you want to mount.
export MOUNT_CREDENTIALS="fs.s3a.access.key=<S3 tenant key>, fs.s3a.secret.key=<S3 tenant secret key>, fs.s3a.endpoint=<your-storagegrid-end-point.com> , fs.s3a.connection.ssl.enabled=true"4. Mount the S3 storage on your SQL Server Big Data Cluster.
azdata bdc hdfs mount create --remote-uri s3a://<S3 bucket name>/ -m /mounts/<name your mount>
Note: Azdata creates the mount for you with the name you enter.
5. Use the following command to verify that the mount was successfully created.
azdata bdc hdfs mount status --output table
sample output: Mount Remote State -------------- ---------------- ------- /mounts/netapp s3a://msbigdata/ Ready
Note: It might take up to 2 minutes for the mount to be ready.
We will add a YouTube video on SQL Server Big Data Clusters soon.
To learn more about how StorageGRID object storage can benefit your environment, visit the StorageGRID page or the StorageGRID documentation center to access more resources for your specific use cases.
Joseph Kandatilparambil
Joseph Kandatilparambil is Technical Marketing Engineer for StorageGRID, with over 7 years of experience in the storage industry. Joseph helps with customer driven innovation by empowering customers with solutions that help them focus on driving their product forward and expand their horizons. Outside of work, Joseph enjoys kite-surfing, rock climbing and hiking.