How to Build a Data Pipeline for Autonomous Driving


Santosh Rao
Last time I talked about how automotive companies are using AI for a wide variety of use cases from autonomous vehicles to connected cars to mobility as a service.
This time I want to dig into ways to leverage the data engineering and data science technologies I’ve been discussing to solve autonomous driving challenges. I’ll explore approaches for gathering data from test and survey vehicles and ways to build appropriate data pipelines to satisfy data needs throughout the process.
Autonomous Driving Challenges
Most companies are already offering increasingly sophisticated advanced driver assistance systems (ADAS) as stepping stones toward Level 4 autonomy and beyond. If you’re not completely familiar with the many players already competing in the self-driving space, Bloomberg has a recent summary.
Autonomous vehicle (AV) development projects face significant data challenges. Each car deployed for R&D generates a mountain of data:
- How do you create a pipeline to move data efficiently from vehicles in the field to your training cluster to train deep neural networks?
- How do you efficiently prepare image and other sensor data and label (annotate) data for DNN training?
- How much storage and compute will you need to train your neural networks? Should your training cluster be on-premises or in the cloud?
- How do you correctly size infrastructure for your data pipelines and training clusters including storage needs, network bandwidth, and compute capacity?
- What other data flows do you need to take into account?
Data Pipeline for Autonomous Vehicle Development
An autonomous vehicle development program has many components, each with unique data management requirements. The volume and diversity of data creates unique challenges in all areas. This section describes some of the specific data and computing challenges in a number of key areas:
- Data collection from test vehicles with full sensor suites
- Training DNNs using labeled data derived from test vehicles
- Simulation to test the performance of DNNs and to create additional training data
- Mapping to create detailed representations of physical environments
The following figure summarizes pipeline components at a high level.
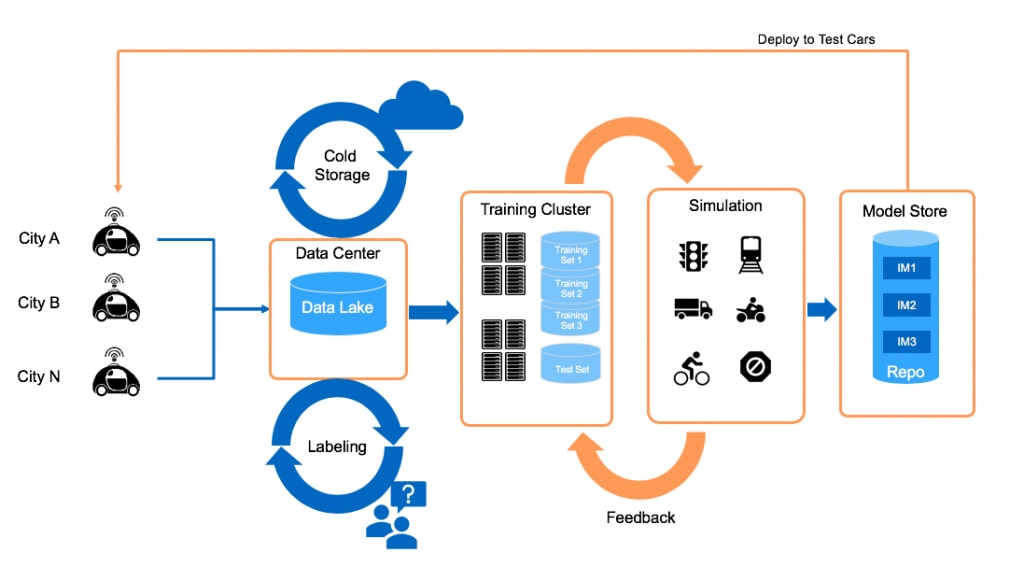
Data Collection from Test Vehicles
During the data collection process, data must be ingested from each test car in the fleet. The amount of data you actually collect per car will vary depending on your sensor suite.
Guideline: Plan for 1-5TB per hour per car during initial training and update your plan as you receive actual results.
You may find that data collection from test vehicles falls into two phases:
- Initial training. If you are training DNNs from scratch, you will need to collect all driving data from your test cars.
- Transfer learning. Once your DNNs begin to work well, you may only need or want to collect data from situations where the test cars don’t perform well or where safety drivers take control.
During initial training in particular, it’s unlikely that you’ll be able to transmit data from each car over cellular networks because of both bandwidth limitations and cost. It’s more likely that you’ll store the data on each car and download it periodically when the car reaches a garage or depot.
This requires data storage infrastructure both in each test car and in each depot location. As your test fleet expands to different cities, you may need to add hub locations to aggregate data for each city. Because there’s no single one-size-fits-all solution, NetApp offers a range of options to address data collection from test cars, including:
- In-vehicle ruggedized data collector solutions
- Storage options optimized for garage and hub locations to enable your AV operations to scale
- NetApp cloud services for near-the-cloud and in-the-cloud storage to support both cloud ingest and burst-to-cloud needs
- Data mule solutions for bulk data transport to overcome network limitation
NetApp solutions scale to meet your capacity and I/O performance needs as your program scales from petabytes to exabytes.
Aggregating Data
As data is collected from test vehicles, it’s typical to aggregate it into a data lake, either in a data center or in the cloud (or both). A data lake usually takes the form of a Hadoop deployment with HDFS, an object store, or a file store.
An improperly implemented data lake can become a bottleneck as data accumulates, so it’s important to give this careful consideration. Because of the amount of data being collected, the current best practice for autonomous vehicle development programs is to have the data lake and training cluster on-premises, possibly with some parts of the project in the cloud as well.
The considerations for architecting a data lake for deep learning were covered in a general way in these NetApp white papers:
The guidelines in these papers are directly applicable to AV development; you just have to scale everything for the amount of data you anticipate and to achieve the data throughput you’ll need.
Guideline: Plan for at least 2PB of data per test car per year.
Phrased differently, for every 10 cars plan for at least 20PB of data lake capacity per year. Over time, much of the data you’ve gathered may be infrequently accessed, so some form of cold storage may be desirable as well. NetApp offers a variety of solutions to satisfy these needs:
- NetApp FAS and NetApp All Flash FAS (AFF) systems can be architected to satisfy a broad range of data lake needs in terms of both capacity and performance.
- For archiving cold data, NetApp FabricPool technology migrates data to object storage automatically based on defined policies.
- NetApp StorageGRID software and solutions provide advanced object storage that can be used in conjunction with FabricPool or standalone.
- NetApp Cloud Data Services including Cloud Volumes Service and NetApp Kubernetes Service (both available for AWS, Google Cloud, and Azure) can accelerate your AV operations in the cloud.
Labeling Data
One of the biggest bottlenecks in AV development may be the need for labeled training data. Especially during initial training, you may require millions of labeled images to enable your algorithms to correctly identify the variety of objects that can appear during autonomous driving: other vehicles, road markings, signage, curbs, pedestrians, bicyclists, the complete list is long.
If you anticipate 2PB of data per test car per year, that translates to roughly 1 billion images, of which 3 million or more may need to be labeled. This labeling is still largely accomplished by humans.
Many companies accomplish labeling using an outsourced workforce. This means making the necessary data accessible to those workers, often in another part of the world. It may be necessary to move data into the cloud to accomplish this, despite egress costs for labeled images.
NetApp is collaborating with a number of companies that are innovating in data preparation and data labeling automation to accelerate data labeling tasks for AV programs and other use cases. You can find out more about data preparation, data labeling, and related tasks in this recent NetApp white paper:
Training DNNs
While there’s no single approach to designing DNNs for autonomous driving, it’s typical to use an ensemble approach, with separate DNNs carrying out a variety of discrete tasks. For instance, you may have DNNs specifically for path planning, object identification, reading signs, detecting the state of stoplights, and other functions.
In practice, this means that you won’t just be training a single DNN, you’ll likely be training multiple DNNs—including different approaches for each class of problem—and doing so on a regular basis. This is important to recognize, because it significantly increases the scale of computation required.
The current state of the art in deep learning training clusters is a scale-out cluster, potentially with hundreds of servers and 4 to 8 GPUs per server. From an I/O standpoint, you have to keep all those GPUs 100% busy; you have to avoid leaving GPUs sitting idle waiting for data.
NetApp’s Data ONTAP architecture uniquely satisfies deep learning requirements for AV training. The data lake can be designed using hybrid FAS nodes, which can stream data into the training cluster with extremely high bandwidth. AFF nodes supporting the training cluster deliver bandwidth up to 18GB/sec per two-controller HA pair and sub-500 microsecond latencies, providing the bandwidth to support many I/O streams in parallel. Other flash solutions can’t achieve these latencies or bandwidth. NetApp also offers a technology roadmap that allows you to continue to grow the I/O performance of your AV pipeline as your needs grow.
The NVIDIA DGX-1 deep learning system incorporates 8 NVIDIA GPUs with supporting CPUs and a high-performance interconnect. For AV applications, a single DGX-1 can train 300K labeled images on one DNN in one day. Assuming you have 3 million labeled images per test car, and 10 DNNs with multiple experiments running in parallel, you may require up to 100 DGX-1 per test car.
Guideline: Plan for 100 DGX-1 systems (or the equivalent) per test car for DNN training.
NetApp has partnered with NVIDIA to offer ONTAP AI. Powered by NVIDIA DGX deep learning systems and NetApp all-flash storage, ONTAP AI lets you simplify, accelerate, and scale your pipeline for AV development. ONTAP AI is available with the NVIDIA DGX-1 or the NVIDIA DGX-2, offering up to 300GB/sec throughput to achieve 99% GPU utilization. Here is a depiction of a scale-out ONTAP AI implementation with a 24-node A800 cluster, driving 108 DGX-1’s.

For Cisco-UCS-centric data centers, NetApp and Cisco have partnered to offer FlexPod AI.
Simulation/Re-simulation
For most AV development programs, simulation is a critical component of the process. Simulation may allow DNNs to be quickly tested by simulating a variety of driving environments and by playing back real-world scenarios gathered from test cars (as well as variations on those scenarios).
Simulation in itself is an area of substantial research and innovation. A number of companies are focused specifically on realistic simulation for autonomous vehicles and robots. There are a variety of aspects to achieving successful simulation:
- Achieving the necessary resolution and delivering realistic inputs for all vehicle sensors in real-time
- Providing the necessary inference performance for the ensemble of DNNs under study, potentially with numerous simulation streams running in parallel.
- Accurately modeling the behavior of cars, bicycles, pedestrians, and any other non-stationary elements.
3D Mapping
Another critical element of many AV programs is high-definition 3D mapping. Many AV approaches utilize high-definition maps of the routes to be driven. Comparing output from a vehicle’s sensor array to an existing map is considered by many as a way to simplify the process of path planning.
If this is the approach you intend to use, you first have to decide whether you’ll do your own mapping or rely on data from someone else. A number of startups and other companies are working on mapping data sets.
Doing your own mapping may offer a competitive advantage, and it may allow you to create HD maps that are more closely matched to your planned sensor arrays, but also represents a substantial additional investment. If you plan on creating your own high-resolution 3D maps for target regions, you’ll need survey cars outfitted with the appropriate sensors to gather the necessary data and data pipelines to ingest, process, and deliver the mapping data wherever it’s required. The mapping process will need to expand to new regions as your program expands, and maps may need to be refreshed at regular intervals.
More Information and Resources
NetApp is working to create advanced tools that eliminate bottlenecks and accelerate results for all aspects of AV development from data ingest, to training, to simulation so that data management and infrastructure never become a bottleneck to your AV development efforts. We are working to build an ecosystem of partners that can help with all aspects of your AV project.
NetApp ONTAP AI and NetApp Data Fabric technologies and services can jumpstart your company on the path to success. Check out these resources to learn about ONTAP AI.
- Solution Brief: NetApp ONTAP AI
- White Paper: Building a Data Pipeline for Deep Learning
- White Paper: Edge to Core to Cloud Architecture for AI
- NetApp Validated Architecture: ONTAP AI – NVIDIA DGX-2 POD with NetApp AFF A800
- Customer Story: Cambridge Consultants Breaks Artificial Intelligence Limits
Previous blogs in this series:
- Is Your IT Infrastructure Ready to Support AI Workflows in Production?
- Accelerate I/O for Your Deep Learning Pipeline
- Addressing AI Data Lifecycle Challenges with Data Fabric
- Choosing an Optimal Filesystem and Data Architecture for Your AI/ML/DL Pipeline
- NVIDIA GTC 2018: New GPUs, Deep Learning, and Data Storage for AI
- Five Advantages of ONTAP AI for AI and Deep Learning
- Deep Dive into ONTAP AI Performance and Sizing
- Bridging the CPU and GPU Universes
- Make Your Data Pipeline Super-Efficient by Unifying Machine Learning and Deep Learning
- Artificial Intelligence in the Automotive Industry
Santosh Rao
Santosh Rao is a Senior Technical Director and leads the AI & Data Engineering Full Stack Platform at NetApp. In this role, he is responsible for the technology architecture, execution and overall NetApp AI business. Santosh previously led the Data ONTAP technology innovation agenda for workloads and solutions ranging from NoSQL, big data, virtualization, enterprise apps and other 2nd and 3rd platform workloads. He has held a number of roles within NetApp and led the original ground up development of clustered ONTAP SAN for NetApp as well as a number of follow-on ONTAP SAN products for data migration, mobility, protection, virtualization, SLO management, app integration and all-flash SAN. Prior to joining NetApp, Santosh was a Master Technologist for HP and led the development of a number of storage and operating system technologies for HP, including development of their early generation products for a variety of storage and OS technologies.