Choosing the Right Disaster Recovery Solution for Your Enterprise Applications


Ebin Kadavi

In today’s constantly connected global business environment, protecting your data from disasters (natural disasters, multiple disk failures, and man-made mishaps) and recovering applications instantly without data loss requires a cost-effective and reliable data protection strategy. IT demands are changing rapidly, requiring the rapid repurposing and reconfiguration of data centers. Using multiple new management tools is not a viable option. Enterprises are looking for a single business continuity solution that meets all their requirements—from protecting a small number of volumes and single applications to protecting large clusters and multisite environments.
Native Application Replication vs Storage Replication
Conventionally, most enterprise-grade databases and applications provide technology to handle their own replication, both synchronously and asynchronously. Database replication tools like Oracle Data Guard and others only work on individual databases and thus have the advantage that the standby database is continuously in recovery mode. Therefore, it is very fast and easy to activate the standby database as the new primary in the event of a disaster.
The real challenge occurs when there is a minor bug in the software stack or in the config settings that renders the entire standby database useless. A bug could also interfere with the failover of the remaining application servers, middleware, monitoring systems, and so on.
Despite these facts, many enterprises use different replication mechanisms for different applications. For example, they might use a separate tool for Oracle, SQL Server, MySQL, IBM DB2, and so on, which makes overall IT management highly complex from the CXO perspective.
An alternative to application replication is storage mirroring. If the mirrors are in sync, then you can be certain that you can fail over in case of a disaster because all the data is present in the mirror. You can also speed up the overall recovery and application startup process by configuring automated storage failover rather than performing a manual DR operation. In the case of end-to-end DR, it might take a few minutes to mount the storage devices to the DR servers and bring up the databases to use the remote data set.
Solve Your DR Problem Cost Effectively with NetApp
Today, various leading storage vendors offers protection at various scales with extra hardware, but most of these options are not cost effective and reliable enough for relational databases. Furthermore, using an expensive secondary facility for value-added purposes such as development and testing and analytics is relatively limited.
The cost-effective and reliable NetApp MetroCluster® and SnapMirror® technologies were designed from scratch as business continuity tools (for example, DR, backup, and restore scenarios). By their architectural design, these products do not depend on any host platform hardware, operating system, driver, database, application, filesystem, volume manager, or any other component on the application host.
NetApp MetroCluster is a continuous-availability solution that protects critical data and provides data availability 24/7, and it is also a set-it-once technology. After MetroCluster instances are correctly configured, you only need to monitor and administer them. As the environment grows with new applications and workloads, data is automatically replicated and protected. You do not incur any change management or administration overhead. MetroCluster can be configured in a number of different ways depending on your environment as shown in the below figure. With the latest releases of NetApp ONTAP® storage, MetroCluster IP ISL can cover a maximum distance of up to 700 km with a maximum round trip latency of 10ms.
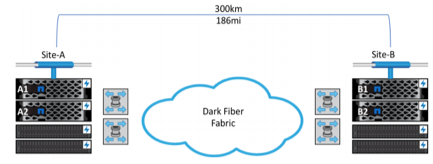 Figure 1) MetroCluster configuration over FC[/caption]
Figure 1) MetroCluster configuration over FC[/caption]
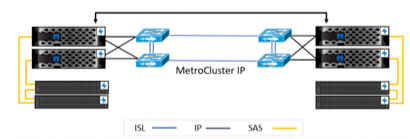 Figure 2) MetroCluster configuration over IP[/caption]
Figure 2) MetroCluster configuration over IP[/caption]
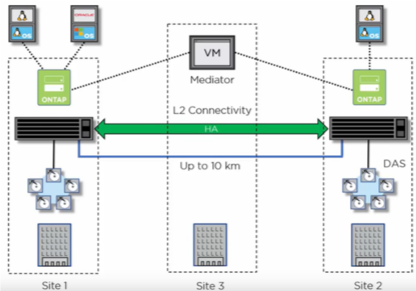 Figure 3) MetroCluster SDS[/caption]
Figure 3) MetroCluster SDS[/caption]
Rise of SnapMirror Synchronous
NetApp SnapMirror Synchronous (SM-S), introduced in NetApp ONTAP 9.5, offers the flexibility to synchronously protect a subset of volumes in a cluster rather the entire cluster as in MetroCluster. In addition, replication can be between ONTAP storage systems that are on different platforms. For example, SM-S can be set up between FAS and AFF, between FAS and ONTAP Select, or between AFF and ONTAP Select.
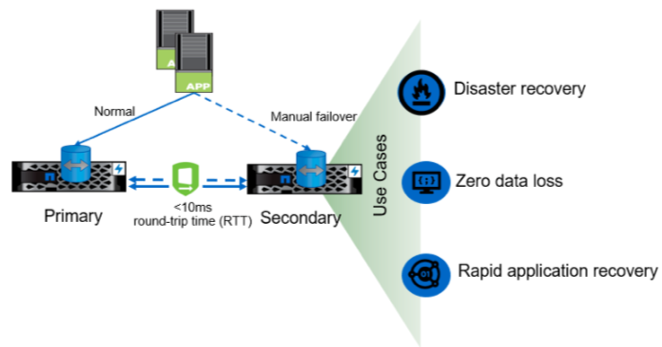 Figure 4) Achieving a zero-RPO DR solution for applications using SnapMirror synchronous (SM-S)[/caption]
Figure 4) Achieving a zero-RPO DR solution for applications using SnapMirror synchronous (SM-S)[/caption]
SM-S does not require any new or special hardware, software, or networking capabilities, which significantly lowers the overall cost of the solution. SM-S is appropriate for relatively short distances of 150 km or less between ONTAP storage systems. With less than 10 milliseconds of round-trip time, you can achieve a zero recovery point objective (RPO) and a near-zero recovery time objective (RTO).
NetApp SM-S replication offers two modes of replication to a failover destination.
- StrictSync: In this mode, SM-S fails the client I/O if there is a failure to synchronously replicate to the mirror copy.
- Sync: In this mode, SM-S continues the client I/O even after a failure of synchronous replication to the mirror copy. The mirror status is marked as OutOfSync and an automatic resync process is started to return the relationship back to In Sync.
For relational databases, it is essential to retain dependent write order consistency when the data is spread across more than a volume in the storage. When using the StrictSync mode of replication, application I/O automatically retains write order consistency. However, it is critical to preserve network RTT latency within 10ms.
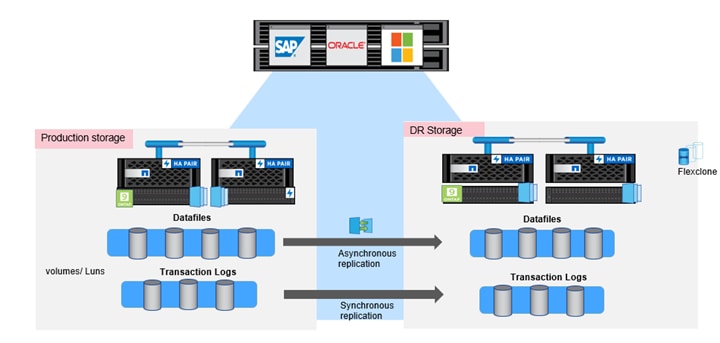 Figure 5) Storage layouts for achieving zero-RPO DR solutions[/caption]
Figure 5) Storage layouts for achieving zero-RPO DR solutions[/caption]
An alternative method is to asynchronously replicate datafiles volumes and synchronously replicate transaction logs to retain an RPO of zero. For more information on how to enable synchronous replication for Oracle database workloads and failover to secondary DR storage, see this video.
Similarly, applications can be resynced to their primary storage by performing a failback during the next maintenance window in a simple three-click process using NetApp System Manager.
Summary
The most important part of a DR strategy is evaluating the overall RPO and RTO, depending on the nature of the disaster, which could be limited to storage, databases, or the network or potentially could affect the entire site.
Choosing a database replication technology, such as Oracle Data Guard, Oracle GoldenGate, Availability groups, or other options, might be acceptable for few mission critical databases. However, managing a large scale infrastructure in this way with hundreds or thousands of different databases along with their middleware and front-end applications is too complex and expensive.
Simple and efficient storage DR solutions like NetApp SnapMirror and NetApp MetroCluster are significantly more cost effective than application replication tools and can be easily managed by IT generalists without the need for an additional expertise. NetApp recommends evaluating both of these synchronous replication solutions and deciding between them based on your specific requirements. To learn more about NetApp synchronous and asynchronous replication solutions, see the SnapMirror and MetroCluster product pages.
Ebin Kadavi
Ebin Varghese Kadavy is a Technical Marketing Engineer in the Database solutions team. He is an Experienced Database Specialist with a demonstrated history of working more than 10 years in the information technology and services industry. He is Skilled in managing Oracle Databases, PostgreSQL Database, MySQL, Cassandra, Oracle Apps EBS, WebLogic Administration, and Unix.