Bridging the CPU and GPU Universes


Santosh Rao
 Data center technology moves in cycles. In the current cycle, standard compute servers have largely replaced specialized infrastructure. This holds true in both the enterprise and the public cloud.
Data center technology moves in cycles. In the current cycle, standard compute servers have largely replaced specialized infrastructure. This holds true in both the enterprise and the public cloud.
Although this standardization has had tremendous benefits, enabling infrastructure and applications to be deployed more quickly and efficiently, the latest computing challenges threaten the status quo. There are clear signs that a new technology cycle is beginning. New computing and data management technology are needed to address a variety of workloads that the “canonical architecture” has difficulty with.
NetApp and NVIDIA share a complementary vision for modernizing both the data center and the cloud. We’re using GPU and data acceleration technologies to address emerging computing workloads like AI, along with many other compute-intensive and HPC workloads, including genomics, ray tracing, analytics, databases, and seismic processing and interpretation. Software libraries and other tools offer support to teams moving applications from CPUs to GPUs; RAPIDS is one recent example that applies to data science.
Server Sprawl and the Emergence of GPU Computing
Server sprawl is a painful reality in many data centers. Even though CPUs get more powerful every year, the total number of servers keeps climbing because:- More CPUs are needed to support the growth of existing workloads
- More CPUs are needed to run new workloads
Beginning in the early 2000s, computer scientists realized that the capabilities that make GPUs well suited for graphics processing could be applied to a wide variety of parallel computing problems. For example, NetApp began partnering with Cisco, NVIDIA, and several energy industry partners to build GPU computing architectures for seismic processing and visualization in 2012. Today’s fastest supercomputers are built with GPUs, and GPUs play an important role in high-performance computing (HPC), analytics, and other data-intensive disciplines.
Because a single GPU can take the place of hundreds of CPUs for these applications, GPUs hold the key to delivering critical results more quickly while reducing server sprawl and cost. For example, a single NVIDIA DGX-2 system takes just 10U of rack space, cutting the infrastructure footprint by 60 times at one-eighth of the cost, compared to a 300-node CPU-only cluster to do the same work.
Data Sprawl Requires a Better Approach to Data Management
The same architectural approach that contributes to server sprawl also creates a second—and more insidious—problem: data sprawl. With the sheer amount of data that most enterprises are dealing with—including relatively new data sources such as industrial IoT—data has to be managed very efficiently, and you have to be extremely judicious with data copies. However, you may already have multiple, separate server clusters to address various needs such as real-time analytics, batch processing, QA, AI, and other functions. A cluster typically contains three copies of data for redundancy and performance, and each separate cluster may have copies of exactly the same datasets. The result is vast data sprawl—with much of your storage consumed to store identical copies of the same data. It’s nearly impossible to manage all that data or to keep copies in sync.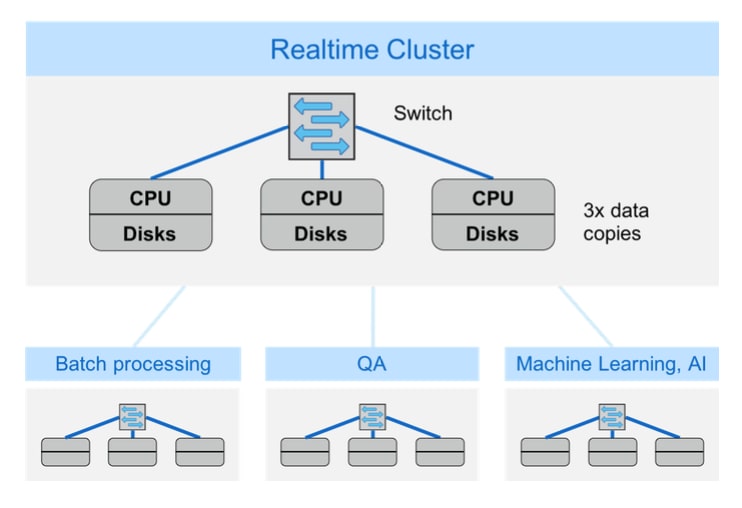 Many enterprises have separate compute clusters to address different use cases, leading to both server sprawl and data sprawl.[/caption]
Complicating the situation further, the I/O needs of the various clusters shown in the figure are different. How can you reduce data sprawl and deliver the right level of I/O at the right cost for each use case? A more comprehensive approach to data is clearly needed.
Many enterprises have separate compute clusters to address different use cases, leading to both server sprawl and data sprawl.[/caption]
Complicating the situation further, the I/O needs of the various clusters shown in the figure are different. How can you reduce data sprawl and deliver the right level of I/O at the right cost for each use case? A more comprehensive approach to data is clearly needed.
Is the Cloud Adding to Your Server and Data Sprawl Challenges?
Most enterprises have adopted a hybrid cloud approach, with some workloads in the cloud and some on the premises. For example, for the workloads shown in the figure, you might want to run your real-time and machine-learning clusters on your premises, with QA and batch processing in the cloud. Even though the cloud lets you flexibly adjust the number of server instances you use in response to changing needs, the total number of instances at any given time is still large and hard to manage. In terms of data sprawl, the cloud could actually make the problem worse. Challenges include:- Moving and synching data between on-premises data centers and the cloud
- Delivering necessary I/O performance in the cloud
Tackling Sprawl with NetApp and NVIDIA
If you’re struggling with server and data sprawl challenges, the latest data management solutions from NetApp and GPU computing solutions from NVIDIA may be the answer, helping you build an effective bridge between existing CPU-based solutions and GPU-based ones.- NVIDIA leads the industry in GPU computing. GPU acceleration delivers results fast and reduces server sprawl. NVIDIA software tools make it easier than ever to get started.
- NetApp helps you manage data more efficiently, eliminating the need for unnecessary copies. Data from dispersed sources becomes part of a single data management environment that makes data movement seamless. Advanced data efficiency technologies reduce your storage footprint and further reduce data sprawl. Data tiering allows you to deliver the right I/O performance for every workload, ensuring that GPUs aren’t stalled waiting for data.
- Unifying Machine Learning and Deep Learning Ecosystems with Data
- The Promise of GPU Computing and a Unified Data Platform
More Information and Resources
NetApp and NVIDIA are working to create advanced tools that eliminate bottlenecks and accelerate results—results that yield better business decisions, better outcomes, and better products.NetApp ONTAP® AI and NetApp Data Fabric technologies and services can jumpstart your company on the path to success. Check out these resources to learn about ONTAP AI:
- Solution Brief: NetApp ONTAP AI
- White Paper: Edge to Core to Cloud Architecture for AI
- NetApp Validated Architecture: NetApp ONTAP AI Powered by NVIDIA
- Tech Report: Moving Data from Big Data Analytics to Artificial Intelligence
- Customer Story: Cambridge Consultants Breaks Artificial Intelligence Limits
- Is Your IT Infrastructure Ready to Support AI Workflows in Production?
- Accelerate I/O for Your Deep Learning Pipeline
- Addressing AI Data Lifecycle Challenges with Data Fabric
- Choosing an Optimal Filesystem and Data Architecture for Your AI/ML/DL Pipeline
- NVIDIA GTC 2018: New GPUs, Deep Learning, and Data Storage for AI
- Five Advantages of ONTAP AI for AI and Deep Learning
- Deep Dive into ONTAP AI Performance and Sizing
Santosh Rao
Santosh Rao is a Senior Technical Director and leads the AI & Data Engineering Full Stack Platform at NetApp. In this role, he is responsible for the technology architecture, execution and overall NetApp AI business. Santosh previously led the Data ONTAP technology innovation agenda for workloads and solutions ranging from NoSQL, big data, virtualization, enterprise apps and other 2nd and 3rd platform workloads. He has held a number of roles within NetApp and led the original ground up development of clustered ONTAP SAN for NetApp as well as a number of follow-on ONTAP SAN products for data migration, mobility, protection, virtualization, SLO management, app integration and all-flash SAN. Prior to joining NetApp, Santosh was a Master Technologist for HP and led the development of a number of storage and operating system technologies for HP, including development of their early generation products for a variety of storage and OS technologies.