Apache Spark plays in the NetApp data analytics playground


Karthikeyan Nagalingam
 To understand the development of data analytics, let’s use the analogy of automotive transmission development to improve control when changing car speed. We started out using manual transmission and progressed to semi-automatic for a smooth transition from manual to automatic transmission. Now most cars only have an automatic transmission. Similarly in data analytics, we started with a relational database, progressed to distributed analysis with disk operations, and then introduced in-memory for prediction and data analysis.
To understand the development of data analytics, let’s use the analogy of automotive transmission development to improve control when changing car speed. We started out using manual transmission and progressed to semi-automatic for a smooth transition from manual to automatic transmission. Now most cars only have an automatic transmission. Similarly in data analytics, we started with a relational database, progressed to distributed analysis with disk operations, and then introduced in-memory for prediction and data analysis.
Apache Spark is a programming framework for writing Hadoop applications that work directly with the Hadoop Distributed File System (HDFS) and other file systems, such as NFS and object storage. Apache Spark is a fast analytics engine designed for large-scale data processing that functions best in our NetApp® data analytics playground. It is more efficient than MapReduce for data pipelines and interactive algorithms. Apache Spark also mitigates the I/O operational challenges you might experience with Hadoop.
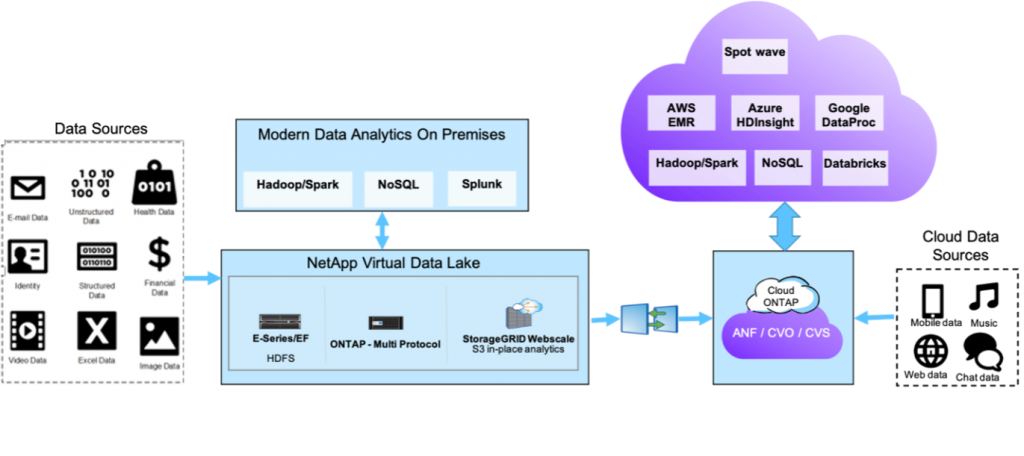 The NetApp modern data analytics playground[/caption] Before you decide to use Apache Spark workload with NetApp storage to overcome your large-scale data processing challenges, you might need answers to questions such as:
The NetApp modern data analytics playground[/caption] Before you decide to use Apache Spark workload with NetApp storage to overcome your large-scale data processing challenges, you might need answers to questions such as:
- Why would I use NetApp for Apache Spark workload?
- What are the benefits of using NetApp with Apache Spark?
- When should I use StorageGRID for Apache Spark?
- What NetApp storage controller should I use for my in-memory engine?
The requirements for Apache Spark workload with NetApp storage
We understand your data analytics challenges based on our findings from many Proof-Of-Concept (POC) studies with large-scale customers in the financial services and automotive industry.DAS versus shared storage: You want to modernize your analytics infrastructure from a server-based direct-attached storage (DAS) setup to a shared data lake.
Scale compute and storage: Because your compute servers are busy running analytics queries as well as serving data, you cannot scale your servers and storage independently. Going forward, it is not feasible to continue adding servers and storage to keep up with your increasing data quantity and analytics demands.
Sharable data and GPU: Your data is locked up in local HDFS clusters and you would like to share it between multiple clusters and applications and be future-ready for using GPUs and modern analytics tools.
We used your data analytics challenges to define the deliverables for a storage solution using Apache Spark workload with NetApp storage.
The Apache Spark workload with NetApp storage solution
The following use case is a great example of how to run Apache spark workload with NetApp storage for a quantitative finance analytics system for our large financial services customers.We ran the Apache spark workload for a write and read operation on NetApp AFF A800 and AFF A700 all-flash storage systems running NetApp ONTAP® software and NetApp StorageGRID® solution, and tested a similar workload running ONTAP with NFS through a MinIO Gateway and an S3A protocol. We validated the Apache Spark test cases in ONTAP, StorageGRID, and MinIO Gateway with NFS.
Our storage solution uses a shared data lake that serves large data compute server farms simultaneously. We based this solution on ONTAP providing easy management and better performance, MinIO Gateway with NFS providing secure access to NFS data through the S3A protocol, and StorageGRID providing access to low-cost storage. We executed an SQL query to create and read the parquet files in ONTAP with NFS. We executed the same query through the S3A protocol on StorageGRID, which took more time because the Spark cluster write operation is different from the NFS write operation.
We generated parquet files using data frames from two random data tables (approximately 2.4TB) by using pySpark Python scripts and performed the write and read operations by using SparkSQL queries on ONTAP on NFS.
 You can see the setup and the query time outputs in the figure above and review our findings below.
You can see the setup and the query time outputs in the figure above and review our findings below.
- We executed the write query in less than 10 minutes for 10 or more Spark worker nodes.
- The Spark write query for NFS is faster than S3A protocol (object storage).
- The Spark read query for NFS and S3A show similar performance.
- StorageGRID for object storage is a cost-effective solution for modern data analytics.
The Apache Spark performance throughput
We extrapolated throughput versus the number of Spark worker nodes to find the maximum number of Spark worker nodes that can be supported by each AFF A800 and AFF A700 all-flash storage system.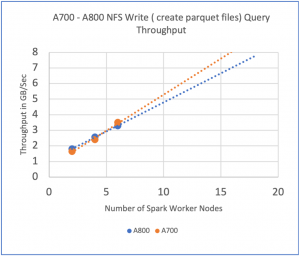
 In the graphs above, we show the number of spark worker nodes for AFF A800 and AFF A700 systems. In addition, when we compare with DAS, we see excellent performance without multiple data copies being used by HDFS. For more information, check out NVA-1157-DEPLOY.
In the graphs above, we show the number of spark worker nodes for AFF A800 and AFF A700 systems. In addition, when we compare with DAS, we see excellent performance without multiple data copies being used by HDFS. For more information, check out NVA-1157-DEPLOY.
The benefits of Apache Spark workload with NetApp storage
With Apache Spark workload with NetApp storage, we built a successful solution with the following benefits:- You can use ONTAP with NFS to separate the disk I/O operations from the server and reduce your I/O wait time by 70%.
- You can get better compute power and performance for Apache Spark workloads and enterprise-grade features with simple management.
- The MinIO Gateway provides you with secure access to NFS data through the S3A protocol.
- StorageGRID provides an object store option to the Spark cluster and a low-cost storage option for Apache Spark workloads.
- You can use NFS for your new data lake infrastructure that helps to share the data among multiple Spark clusters.
- The Apache Spark workload with NetApp storage solution enables you to scale storage and compute independently to bring in infrastructure resources as needed.
- You can successfully use our NetApp ONTAP multiprotocol support in your environment.
For more technical information about Apache Spark workload with NetApp storage solution, check out NVA-1157-DEPLOY.
For more information on Apache Spark workload with NetApp storage Solution for write and read parquet files on ONTAP, check out the following videos:
Write parquet files on ONTAP - Apache Spark workload SparkSQL Read parquet files on ONTAP - Apache Spark workload SparkSQL
Karthikeyan Nagalingam
Karthikeyan Nagalingam is a Principal Technical Marketing Engineer at NetApp for NetApp XCP, Fpolicy, Filesystem Analytics and Antivirus. His previous roles in Emerging Technology Solutions involved in Pre-Sales and Post-Sales technical activities with fields, partners and customers. He holds an Master of Science in Software Systems from Birla Institute of Technology and Science.