AI Workflow Automation with Kubeflow and NetApp


Muneer Ahmad Dedmari
 Artificial Intelligence (AI) requires a robust workflow to handle operations associated with data consolidation and preparation, building and training models, deployment in production environment and monitoring results in real-time. All these components need to work together and implement a workflow strategy throughout the lifecycle to solve real-world business use-cases in timely and efficient manner.
Artificial Intelligence (AI) requires a robust workflow to handle operations associated with data consolidation and preparation, building and training models, deployment in production environment and monitoring results in real-time. All these components need to work together and implement a workflow strategy throughout the lifecycle to solve real-world business use-cases in timely and efficient manner.
Data Engineers and Data Scientists should never worry about where the data exists or on which platforms their algorithms are running, they should rather focus on writing the code, preparing the data and achieve the best algorithmic performance possible.
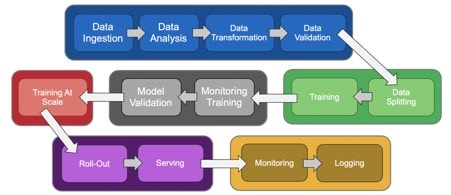 To make the whole AI workflow hassle free, easy to manage and cost effective, there is a need of well structured, portable and scalable AI stack. Kubeflow is one such Machine Learning (ML) platform where different teams and team members (Data Engineer, Data Scientist, DevOps, IT, etc.) share their piece of work without taking care of the underlying infrastructure such as resource management, configuration, infrastructure serving etc.
To make the whole AI workflow hassle free, easy to manage and cost effective, there is a need of well structured, portable and scalable AI stack. Kubeflow is one such Machine Learning (ML) platform where different teams and team members (Data Engineer, Data Scientist, DevOps, IT, etc.) share their piece of work without taking care of the underlying infrastructure such as resource management, configuration, infrastructure serving etc.
Kubeflow by design utilizes Kubernetes (K8s), which makes it possible to execute an end-to-end AI deployment on multiple platforms with different operating systems, underlying hardware and software, on-premises/local environment, in public and private cloud. As there is no such thing as a free lunch, there are some challenges associated with it as well, primarily the work that needs to be done in setting-up a K8s cluster as well as storing and managing datasets and trained models during and after the execution of the entire workflow.
Moreover, a different set of challenges arises when utilizing hybrid multi-cloud setup wherein data availability and consolidation becomes a matter of concern if we need to balance available resources spread across multiple sites.
In this blog we will explore Kubeflow; mainly for AI workflow management, by going through Kubeflow pipeline component. Also, we will discuss how NetApp stack can help to further simplify the entire workflow by providing robust, easy to consume and production ready AI setup.
What is Kubeflow and how does it work?
Kubeflow is an open-source project from Google dedicated to relieving constraints of infusing ML into production-grade solutions. It utilizes all the benefits, like scalability, portability and fault-tolerance, of K8s for Machine Learning.For Data Scientists, it provides a peace of mind as they don't have to worry about setting up the environment every time and managing resources (which we hate). To some extent, it helps focusing on creation and training models, fine-tuning for better performance and ultimately packing it up as a pipeline to make the whole process repeatable and easy to consume.
At the time, Kubeflow mainly consists of six components:
JupyterHub: is used to build and manage interactive Jupyter notebooks with multi-tenancy.
Katib: allows model hyper-parameter tuning on K8s cluster.
Pipelines: is acyclic graph for building and deploying portable, scalable ML workflows based on Docker containers.
Training: allows running and monitoring of training jobs on Kubernetes. At the moment, it supports TensorFlow, PyTorch, Chainer, MXNet and MPI Training jobs.
Serving: of trained models on K8s cluster.
Miscellaneous: components can be used to track and manage metadata associated with ML workflows and supports multi-purpose serverless functions using Nuclio.
To get going with Kubeflow, you at least need a basic understanding of setting up and configuring K8s cluster, which might set off a few people. There are orchestrators available from different cloud vendors which can help to automate the process of running K8s clusters. However, these managed K8s services are mostly cloud vendor specific and hence can’t be used across multiple locations like laptop, on-premises and other cloud vendors.
NetApp Kubernetes Services (NKS) is one solution that makes it possible to spin up and manage Kubernetes cluster on all major public clouds and on premises, that provides the seamless and uniform experience across hybrid multi-cloud platforms. As a Data Scientist, it gives us the full flexibility and control to utilize resources on platforms of our choice, that too without worrying what is going on under the hood, "just few clicks and AI pipeline is up and running, wherever and whenever we want".
For an end-to-end AI workflow automation, we will focus our discussion on Kubeflow Pipeline, that is composed of components. Each pipeline component in turn consists of set of input and output parameters, and containerized package (location of a container image) that includes environment definition and executable code.
In logic, pipeline components are cohesive that allows to perform and manage one step / task (instance of step) in the pipeline’s workflow at a time, such as data collocation and preprocessing, data transformation and validation, model training, continuous trained model deployment in production and so on. It allows us to use different stacks and / or libraries for each step separately e.g. legacy Python 2.7 (about to reach end of life) for pre-processing and Python 3.5 for training models. So, that means there is less dependency from one task to other from code and environment perspective.
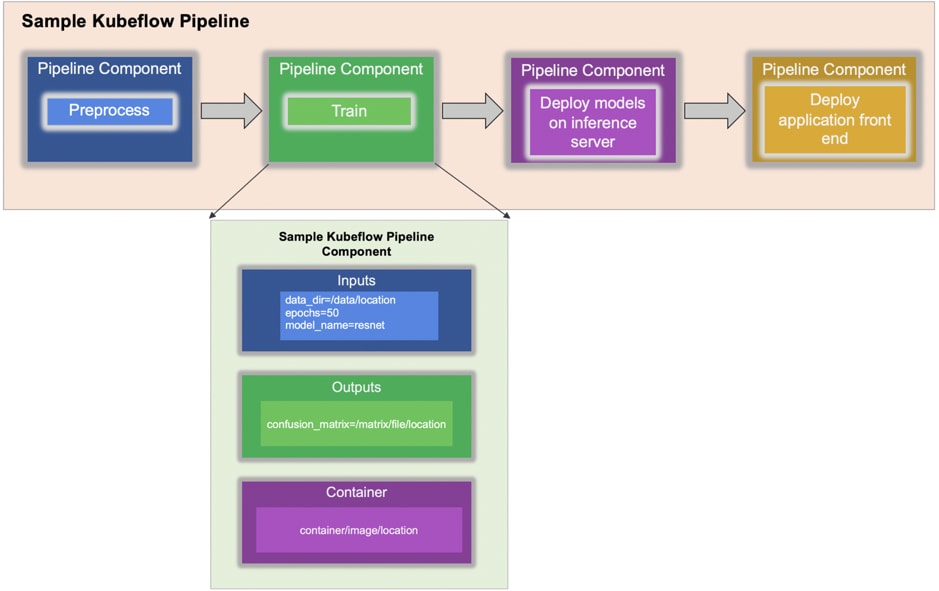
Kubeflow Pipeline’s SDK is used to define the directed acyclic graphical AI workflow and dependency of components are denoted by input and output parameters of tasks. Execution of tasks depends on the output of other tasks within this pipeline. Input parameters of the pipeline can also be modified via pipeline GUI which allows to instantaneously experiment with hyper-parameters, using different datasets from multiple locations, trying different models etc., that too without changing anything in the code or configuration.
Managing Datasets within K8s environment and how can NetApp help
Every ML/DL project requires data for training, evaluation and monitoring. By default, containers are stateless and once job is done all the data is going to be in the wind. Luckily, there is persistent volumes (PVs) that can be used to keep data persistent (as name suggests) after the job is finished. But one needs to create and manage PVs before using and mounting that in containers, in our case Kubeflow pipeline components. NetApp Trident (open-source) plugin creates PVs dynamically, on demand basis and can be mounted in pipeline components as per the need. In short, Data Scientist just needs to ask for the volume, using Persistent Volume Claims (PVCs), and it will be created and attached to the pipeline component.Usually, Data Scientists prefer testing in Jupyter Notebook first (data analysis and visualization, quick model evaluation etc.) before performing training at scale and later move into production. NetApp Trident allows seamless integration with K8s by attaching PVs across Jupyter Notebook and Kubeflow Pipeline components, allowing smooth transition from exploration to exploitation to production. This by itself solves the first challenge described earlier in this article and makes it easier for data scientists and data engineers to leverage K8s without the hassle of manually storing and managing datasets. Trident also eliminates the need for data scientists to learn managing new data platforms as it integrates the data management related tasks through seamless API integration.
From a different perspective, working on hybrid multi-cloud setup arises further complication and additional work to manually sync the state of data across multiple sites for any data update instances. Suppose, raw training data is located on local environment (on-premises) and we are performing preprocessing there and then training of models are performed in public cloud using pre-processed data. Later, if data is updated for example if new data comes in or different preprocessing scheme is used, this requires to explicitly and manually update the data state across all sites so that we have consistent and up to date results avoiding data mismatch disaster.
NetApp Data Fabric overcomes the challenge by allowing Data Scientists and Data Engineers to connect all sites together and have synchronous data state, that too without performing any manual intervention. In other words, it smooths the process of managing AI workflow spread across multiple locations. It also facilitates on-demand based data availability i.e. bring data close to compute and perform analysis, training and validation wherever and whenever needed. Not only it enables data integration but also protection and security of entire data pipeline.
Taking care of ML Versioning with Kubeflow
ML versioning plays a crucial role when it comes to tracking models, sharing work between team members, reproducibility of results, rolling new model versions to production and data provenance. Kubeflow is best at orchestration and managing AI workflow but it’s not providing much when it comes to versioning of data in association with code and configuration to manage the complete state.NetApp ML version control (Snapshot) is capable of capturing point-in-time versions of the data, trained models and logs associated with each Kubeflow pipeline component. As it has rich API support, that makes it easy to integrate with Kubeflow pipeline SDK. While creating the pipeline, we just have to trigger an event based on training state and capture the state of pipeline without changing anything at all in code or containers.
Later, if we want to resume and go to previous version, we just have to recover state by just going to the executed pipeline and restore state from Snapshots, that will get data and logs back to time when that pipeline was executed (kind of time-travel). As NetApp Data Fabric technology stitches different sites (on-premises, private and public cloud) together, allowing to execute and recover pipelines across hybrid multi-cloud. It doesn’t matter if you have versioned your ML project on your local environment (on-premises) and later wants to recover that in cloud or vice-versa, it will take care that all environments behave in same fashion and consistency is maintained across multiple platforms.
Why Kubeflow with NetApp in nutshell
- No need to be expert in K8s for executing Kubeflow AI workflows and performing training and scale
- Seamless execution of Kubeflow pipeline across on-premises / local and cloud (e.g. PoC in cloud and perform training at scale on-premises or vise-versa)
- Easy integration of datasets with Kubeflow pipelines, Jupyter Notebooks and other components
- ML versioning integration without changing anything in code or/and containerized environment
- Single pane of glass management and monitoring of resources (on-prem and cloud)
- Work on platform of your choice (no vendor lock-in)
In the second and following posts of the series, I will be discussing usage of complete stack with the help of use-cases and demos. Find out more:
Meanwhile, if you are interested to play around with this stack on-premises and setting K8s manually, do check:
- Blog: Simplifying DataOps - Persistence in our container world
- Blog: Simplifying DataOps - DataScience as a Service with Kubeflow
- Technical report: AI at Scale with Trident, Kubernetes, and Kubeflow
Muneer Ahmad Dedmari
Working as an AI Solutions Architect – Data Scientist at NetApp, Muneer Ahmad Dedmari specialized in the development of Machine Learning and Deep learning solutions and AI pipeline optimization. After working on various ML/DL projects industry-wide, he decided to dedicate himself to solutions in different hybrid multi-cloud scenarios, in order to simplify the life of Data Scientists. He holds a Master’s Degree in Computer Science with specialization in AI and Computer Vision from Technical University of Munich, Germany.