NetApp ONTAP and Fujitsu for Enterprise AI/ML


Mike McNamara
Computer vision capabilities are having a significant impact in almost every industry, from autonomous vehicles to AI-assisted medical diagnosis. Training the machine learning (ML) algorithms used for computer vision applications creates an extremely demanding workload, requiring massive quantities of data and significant computing power.
To accommodate these workloads, you can use a clustered architecture consisting of NetApp® storage systems and Fujitsu PRIMERGY servers optimized for AI. This NetApp and Fujitsu solution is designed to handle large datasets by using the processing power of GPUs alongside traditional CPUs. The combined solution of PRIMERGY servers and NetApp all-flash storage systems provides an infrastructure that delivers excellent performance and seamless scalability with industry-leading data management.
State-of-the-art NetApp AFF storage systems enable IT departments to meet enterprise storage requirements with industry-leading performance, cloud integration, and best-in-class data management. The Fujitsu PRIMERGY GX2570 server is an extremely powerful deep-learning (DL) platform that benefits from equally powerful storage and network infrastructure to deliver maximum value.
To automatically construct the system infrastructure for this solution, you can use Ansible, a DevOps-style configuration management tool developed by Red Hat. Ansible offers a variety of functional modules from NetApp and Cisco. It includes modules for the Fujitsu PRIMERGY GX2570 M5, for storage such as the NetApp AFF A800 array, and for automatic construction and configuration management of Cisco Nexus 3232C network switches. Ansible makes it easy to add GPU nodes and change the software environment on the host OS, greatly reducing the load on system administrators.
To validate the solution, NetApp and Fujitsu used one NetApp AFF A800 storage system, four Fujitsu PRIMERGY GX2570 servers, and two Cisco Nexus 3232C 100Gb Ethernet (100GbE) switches.
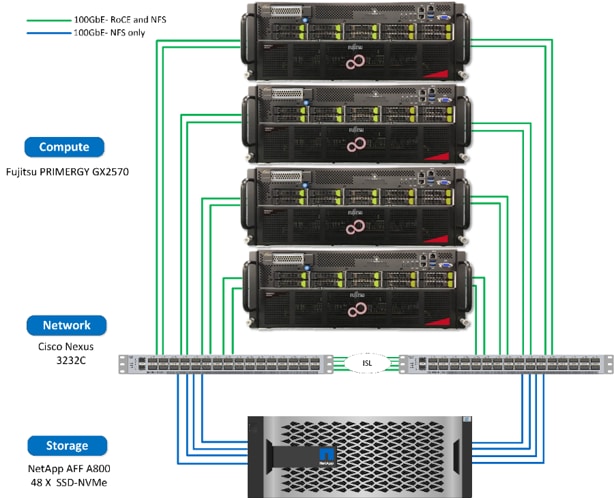 We validated the solution by using the MLPerf v0.6 benchmark models and testing procedure. Each MLPerf training benchmark measures the processing time required to train a model on the specified dataset to achieve the specified quality target. The following table shows the training time involved for each of the models.
We validated the solution by using the MLPerf v0.6 benchmark models and testing procedure. Each MLPerf training benchmark measures the processing time required to train a model on the specified dataset to achieve the specified quality target. The following table shows the training time involved for each of the models.
| Model | Training time result |
| SSD | 19.54 minutes |
| Mask R-CNN | 186.22 minutes |
| ResNet-50 | 94.76 minutes |
| Minigo | 24.97 minutes |
To learn more about the joint solution, read this technical report.
Mike McNamara
Mike McNamara is a senior leader of product and solution marketing at NetApp with 25 years of data management and data storage marketing experience. Before joining NetApp over 10 years ago, Mike worked at Adaptec, EMC and HP. Mike was a key team leader driving the launch of the industry’s first cloud-connected AI/ML solution (NetApp), unified scale-out and hybrid cloud storage system and software (NetApp), iSCSI and SAS storage system and software (Adaptec), and Fibre Channel storage system (EMC CLARiiON). In addition to his past role as marketing chairperson for the Fibre Channel Industry Association, he is a member of the Ethernet Technology Summit Conference Advisory Board, a member of the Ethernet Alliance, a regular contributor to industry journals, and a frequent speaker at events. Mike also published a book through FriesenPress titled "Scale-Out Storage - The Next Frontier in Enterprise Data Management", and was listed as a top 50 B2B product marketer to watch by Kapos.