Achieving Continuous Data Availability with Ethernet Storage Fabrics


Vijay Singh
In today’s global economy that operates 24/7, and is increasingly data driven, availability of data is front and center in the minds of CIOs. A 2017 issue of The Economist stated that in today’s economy the “most valuable resource is no longer oil, but data.” Businesses need continuous availability that goes beyond site-local High Availability and extends to datacenters spread over metro distances. Another facet of availability is the amount of data ‘lost’ when a site failover occurs. Synchronous availability solutions aim to provide an RPO of 0, meaning no application data is lost on failover. Finally, in order to fully monetize their investments customers prefer to deploy solutions that provide active-active configurations.
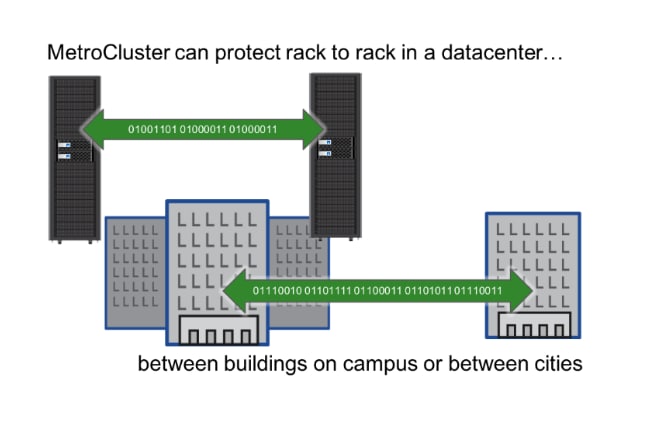 The NetApp MetroCluster synchronous disaster recovery solution has a long-proven history of addressing each one of the above requirements at some of our biggest enterprise customers. ONTAP 9.3 included support for the IP version of MetroCluster that was initially supported on the A700 platform and has since been supported on A800 and A300. This series of blog posts will go into the technical details of the architectural components of the MetroCluster IP solution. In this post, we will explore the Ethernet based transport used for MetroCluster IP.
The NetApp MetroCluster synchronous disaster recovery solution has a long-proven history of addressing each one of the above requirements at some of our biggest enterprise customers. ONTAP 9.3 included support for the IP version of MetroCluster that was initially supported on the A700 platform and has since been supported on A800 and A300. This series of blog posts will go into the technical details of the architectural components of the MetroCluster IP solution. In this post, we will explore the Ethernet based transport used for MetroCluster IP.
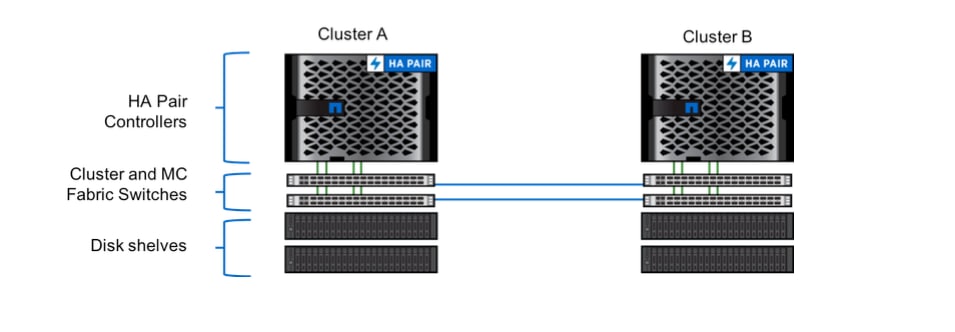
Unified Ethernet Transport
The fundamental building block of the IP solution is the use of Ethernet as the transport between the sites. This means that TCP/IP is used for all planes of replication: NVlog, Storage RAID SyncMirror (RSM) and configuration replication service (CRS). Ethernet has been chosen for a number of important reasons.To begin with, Ethernet speeds have been increasing at a rapid rate. The A800 solution for example, uses a 100 Gb/s Ethernet NIC. Vendors are just coming out with 200 Gb/s NICs and the 400 Gb/s Ethernet specification is expected to be approved soon. The obvious implication is that we can better scale MetroCluster IP performance.
High-speed ports enable combined functionality
These very high capacity ports are making our platforms increasingly port limited. Faster ports means fewer ports. Using such high capacity ports allows MetroCluster IP to use the same Ethernet network port for all three replication planes. This is unlike MetroCluster FC. Fibre channel MetroCluster needed separate ports for RDMA (FC-VI), Storage (FC) and CRS (Ethernet). Since MetroCluster IP unifies all three planes of replication, RDMA, RSM (RAID SyncMirror) and CRS on a single transport, Ethernet, it allows us to support the IP architecture across the entire range of FAS and AFF platforms. In fact, the Ethernet based DR transport will allow us to support MetroCluster on extremely low-end systems using a software-defined RDMA implementation that operates over TCP/IP. The uniformity of the architecture allows us to significantly increase the pace of development.AI/ML applied to the site to site network
Another important benefit of using a software defined network protocol stack is that it allows us to operate over a wide variety of network configurations. The network telemetry that is provided by these protocols not just allows the protocol itself to adjust to different network configurations and conditions, but also allows ONTAP to analyze the inter-site disaster recovery network for anomalies and SLA violations. These insights can be presented to customers as a value-added service. We will publish more information about the work being done in this area in a subsequent blog post. It should be noted that once a solid SLA monitoring framework is in place, the currently specified strict requirements around qualified switches etc. can be relaxed.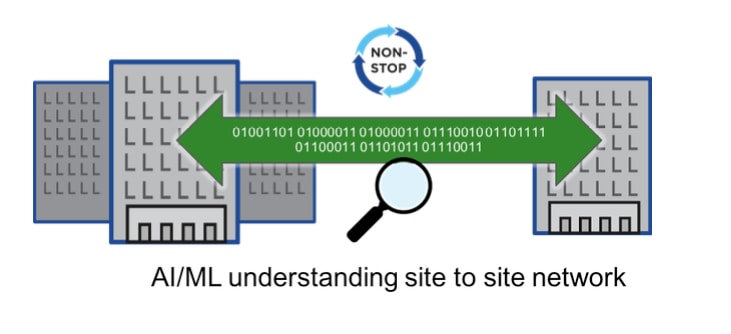 Finally, and most importantly, MetroCluster IP will allow us to dispel the myth that IP is not a “true” storage protocol. Performance data from the A700 MetroCluster product that supports both the FC and IP configurations shows that while FC has an edge in sequential write workloads, IP does much better in small (4KB or 8KB) random write workloads, both in terms of IOPs and latency. The NVMe has just approved a specification supporting NVMe over TCP. And of course, iSCSI has been in use in the SAN space for years. So, it is safe to say that Ethernet/TCP/IP are proven to be ready for any kind of storage workload, and MetroCluster IP is absolutely ready for any prime-time deployment where continuous data availability, proven reliability and industry leading performance is a requirement.
Finally, and most importantly, MetroCluster IP will allow us to dispel the myth that IP is not a “true” storage protocol. Performance data from the A700 MetroCluster product that supports both the FC and IP configurations shows that while FC has an edge in sequential write workloads, IP does much better in small (4KB or 8KB) random write workloads, both in terms of IOPs and latency. The NVMe has just approved a specification supporting NVMe over TCP. And of course, iSCSI has been in use in the SAN space for years. So, it is safe to say that Ethernet/TCP/IP are proven to be ready for any kind of storage workload, and MetroCluster IP is absolutely ready for any prime-time deployment where continuous data availability, proven reliability and industry leading performance is a requirement.
Next
In the next post we will go into greater detail on MetroCluster IP.
Vijay Singh
As a Principal Engineer in the MetroCluster engineering team, Vijay has been working on the evolution of the architecture of the product to match modern datacenter designs. He is the architect of the MetroCluster IP version of the product, and also helped bring the 2-node MetroCluster FC solution to market. His background is in OS network stacks and he is currently actively pursuing projects in data science and machine learning. Prior to NetApp, Vijay worked at Nokia and TCS.